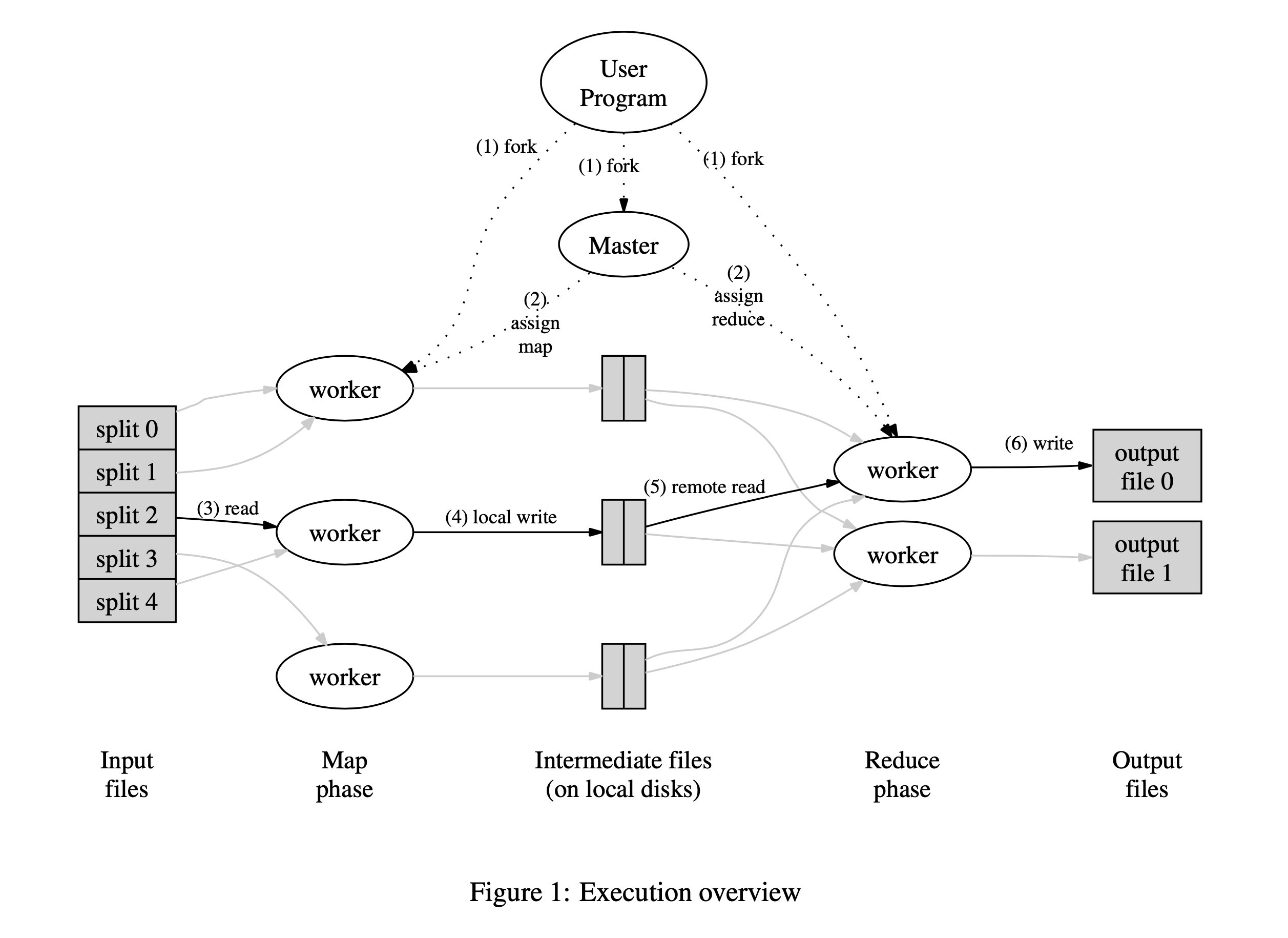
Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
the input keys and values are drawn from a different domain than the output keys and values. Furthermore, the intermediate keys and values are from the same do- main as the output keys and values.
Our C++ implementation passes strings to and from the user-defined functions and leaves it to the user code to convert between strings and appropriate types.
As a reaction to this complexity, we designed a new abstraction that allows us to express the simple computa- tions we were trying to perform but hides the messy de- tails of parallelization, fault-tolerance, data distribution and load balancing in a library.
The run-time system takes care of the details of partitioning the input data, scheduling the program’s execution across a set of machines, handling ma- chine failures, and managing the required inter-machine communication.
The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (con- trollable by the user via an optional parameter). It then starts up many copies of the program on a clus- ter of machines.
One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.
A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The interme- diate key/value pairs produced by the Map function are buffered in memory.
Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all in- termediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.
The reduce worker iterates over the sorted interme- diate data and for each unique intermediate key en- countered, it passes the key and the corresponding set of intermediate values to the user’s Reduce func- tion. The output of the Reduce function is appended to a final output file for this reduce partition.
When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user pro- gram returns back to the user code.
以上过程标号与图中标号对应,文字加粗部分是个人认为需要着重记忆的或“smart”的实现。
3.x Other Problem in Distributed Systems
Section 3的其他内容将在以下做简要概括:
Master Data Structures:Master是整个MapReduce过程的管理者,是Worker间通讯的线人,它将保存任务的状态,以及文件内容在文件系统中的位置等。
并行与分布式计算的正确性需要通过和可能的顺序执行结果进行比较来衡量。本来每个Worker操作的数据对象是不重叠的,因此不会有并发错误,但Worker宕机导致的任务重做可能会使系统各部分看到的状态不同,这时 We rely on atomic commits of map and reduce task outputs to achieve this property. 包括两点:1. Map任务的完成由唯一的Master来仲裁;2. 底层的分布式文件系统提供rename的原子性来保证reduce输出唯一。
Locality:任务调度要考虑局部性,避免数据的网络传输。实际上这点在大型分布式系统中非常重要!
Task Granularity:理论上任务粒度越细越好, Having each worker perform many different tasks improves dynamic load balancing, and also speeds up recovery when a worker fails: the many map tasks it has completed can be spread out across all the other worker machines. 但现实能够支持的调度数量是有限的,请记住以下数字:We often per- form MapReduce computations with M = 200, 000 and R = 5, 000, using 2,000 worker machines.
Backup Tasks:木桶效应,分布式问题就像是管理问题,是调度问题。不同的机器能力不同,快的得等慢的,当然管机器比管人要容易的多。这里举李沐(交大学长,亚马逊CTO,分布式深度学习框架)的五年工作感悟。 When a MapReduce operation is close to completion, the master schedules backup executions of the remaining *in-progress* tasks.
#!/bin/bash go run wc.go master sequential pg-*.txt sort -n -k2 mrtmp.wcseq | tail -10 | diff - mr-testout.txt > diff.out if [ -s diff.out ] then echo "Failed test. Output should be as in mr-testout.txt. Your output differs as follows (from diff.out):" > /dev/stderr cat diff.out else echo "Passed test" > /dev/stderr fi
funcdoMap( jobName string, // the name of the MapReduce job mapTask int, // which map task this is inFile string, nReduce int, // the number of reduce task that will be run ("R" in the paper) mapF func(filename string, contents string) []KeyValue, ) { interFiles := make([]*os.File, nReduce) encoders := make([]*json.Encoder, nReduce) for i := 0; i < nReduce; i++ { interFile, err := os.Create(reduceName(jobName, mapTask, i)) if err != nil { log.Fatal("check: ", err) } interFiles[i] = interFile encoders[i] = json.NewEncoder(interFile) }
funcdoReduce( jobName string, // the name of the whole MapReduce job reduceTask int, // which reduce task this is outFile string, // write the output here nMap int, // the number of map tasks that were run ("M" in the paper) reduceF func(key string, values []string)string, ) {
var KeyValues []KeyValue for i := 0; i < nMap; i++ { interFile, err := os.Open(reduceName(jobName, i, reduceTask)) if err != nil { log.Fatal("check: ", err) } decoder := json.NewDecoder(interFile) for { var kv KeyValue err = decoder.Decode(&kv) if err != nil { break } KeyValues = append(KeyValues, kv) } err = interFile.Close() if err != nil { log.Fatal("check: ", err) } }
funcmapF(filename string, contents string) []mapreduce.KeyValue { // Your code here (Part II). f := func(c rune)bool { return !unicode.IsLetter(c) }
words := strings.FieldsFunc(contents, f) var KeyValues []mapreduce.KeyValue for _, word := range words { KeyValues = append(KeyValues, mapreduce.KeyValue{word, "1"}) } return KeyValues }
funcreduceF(key string, values []string)string { // Your code here (Part II). return strconv.Itoa(len(values)) }
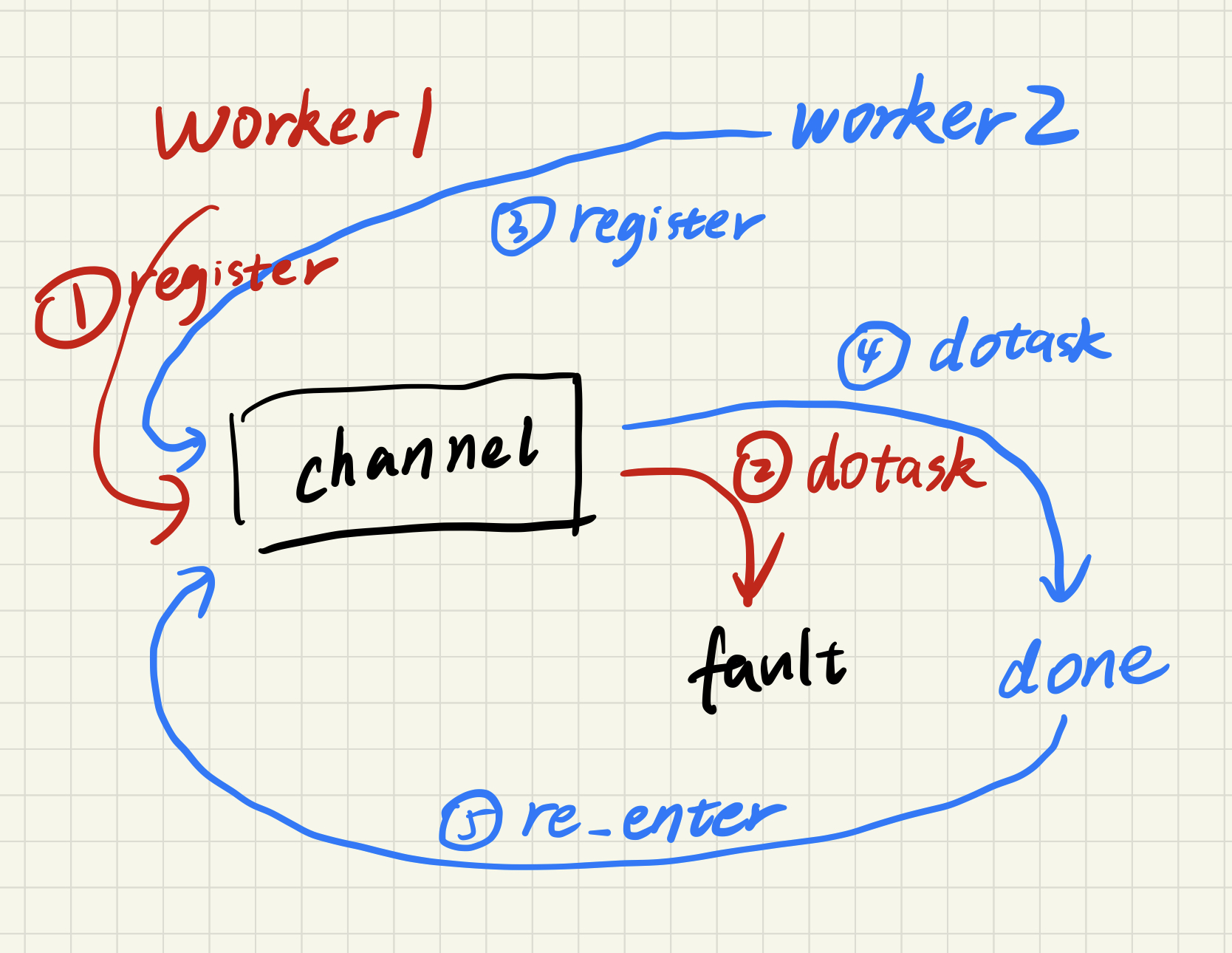
// All ntasks tasks have to be scheduled on workers. Once all tasks // have completed successfully, schedule() should return. // // Your code here (Part III, Part IV). // var wg sync.WaitGroup wg.Add(ntasks) for i := 0; i < ntasks; i++ { taskNumber := i gofunc() { var worker string for { reg := <-registerChan result := call(reg, "Worker.DoTask", DoTaskArgs{ JobName: jobName, File: mapFiles[taskNumber], Phase: phase, TaskNumber: taskNumber, NumOtherPhase: n_other, }, nil) if result == true { worker = reg break } } wg.Done() registerChan <- worker }() } wg.Wait() fmt.Printf("Schedule: %v done\n", phase) }
funcmapF(document string, value string) (res []mapreduce.KeyValue) { // Your code here (Part V). f := func(c rune)bool { return !unicode.IsLetter(c) }
words := strings.FieldsFunc(value, f) var KeyValues []mapreduce.KeyValue for _, word := range words { KeyValues = append(KeyValues, mapreduce.KeyValue{word, document}) } return KeyValues }
funcreduceF(key string, values []string)string { // Your code here (Part V). var reduceValue []string var lastValue string sort.Slice(values, func(i, j int)bool {return values[i] < values[j]}) iflen(values) > 0 { reduceValue = append(reduceValue, values[0]) lastValue = values[0] for _, value := range values { if value != lastValue { reduceValue = append(reduceValue, value) lastValue = value } } } return strconv.Itoa(len(reduceValue)) + " " + strings.Join(reduceValue, ",") }
论文中有If the amount of intermediate data is too large to fit in memory, an external sort is used. 这样的描述,迭代器在数据量大时很常用,但如何构造和实现迭代器依然很陌生,如果简化框架能加入迭代器的实现就更好了。
尝试使用ubuntu启动盘中自带的gcc等组件作为 apt get 的源,而不是通过网络下载。具体参考。但尝试后无法成功,怀疑原因可能是ubuntu桌面版不包含gcc等组件,而博客中的解决的是ubuntu server版的问题。由于重新下载server版,制作启动盘等过程较慢,也没有自己的U盘,因此没有继续尝试重装server版。